It's been a turbulent last few days at the house of A2 Hosting where not only all their Windows hosting, but also a number of Wordpress hosting (as of 23rd April) has come to a standstill. After much pressing by its customers, it has come to light that a malware related security breach caused an outage, not only in one service, but many across A2 Hosting infrastructure.
It's now been 3 days in counting where the outage still persists. Luckily, I managed to move back to my old hosting provider after waiting 2 days patiently for some form of recovery and I'm glad I did! I truly feel sorry for the many others who are still waiting on some form of resolution. I think I managed to get out from under A2 Hosting relatively unscathed.
This whole outage has caused me to not only reflect on my time with A2 Hosting but also hosting providers in general.
The Lies
If I'm honest, the days were counting down after getting infuriated by their support (lack of!) and the lies by their marketing and sales to meet my relatively simple hosting needs. I like to think I'm very scrupulous when it comes to hosting and do my due diligence... In this case, A2 managed to get one over me in that department!
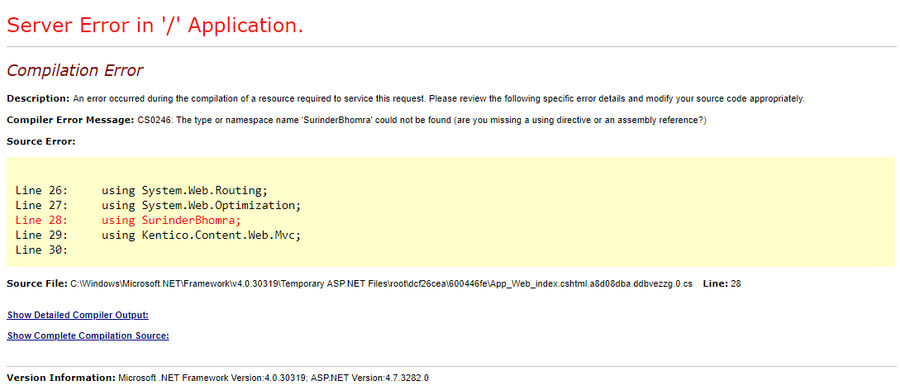
I run a couple of sites on Kentico CMS and it was important to find a hosting company that caters for this platform due to the hardware resources required to run.
Lo and behold...

Judging by that page alone filled me with confidence at a reasonable price with a lot of extras thrown in. I confirmed this was the case by talking at length to the A2 sales team beforehand and was ensured any tier would meet my needs. So I opted for the mid-tier plan - Swift, costing around £125 for 2 years after some nice promotional offers.
Knowing what I know now, I can report that the Swift plan and potentially all the other shared plans do not fit the requirements of a reasonably small Kentico site. Hosting Kentico on A2 Hosting was the bane of my life, as every so often my site would randomly timeout, with only one explanation from their support team:
We suggest you optimize your website with help from your web developer to fix the issue.
After politely requesting more information on the issue and also entertaining the fact I may need to up my hosting, I never really did get any adequate reason. It was always the efficiency of my website to blame.

Lack of Transparency
In light of recent events, transparency isn't one of A2 Hostings strengths (unless when pressed upon by its many customers). When problems arise, I'd prefer to know exactly what is the root cause. Knowing this actually puts more confidence in a hosting provider. I think we all know the feeling when we're not given the full picture.
Our minds have a habit of thinking of a worst-case scenario when we do not have the full picture.
Honesty is the best policy!
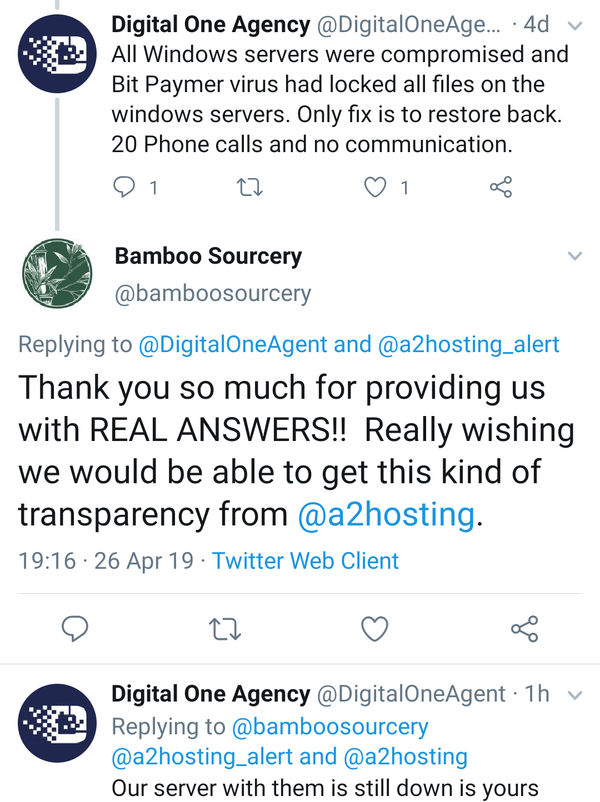
(Example of A2 Hosting Lack of Transparency)
99.9% Uptime Promise
In reality, I don't expect 99.9% uptime from hosting providers as things do happen due to unforeseen circumstances. But I still expect the 98-99% range.
Judging by my uptime monitoring, I have never been blessed with 99.9% uptime during my tenure (1 out of 2-year plan) at A2 Hosting. My site has always encountered timeouts and downtime. The last major outage was around 2 months ago - amounting up to 24 hours downtime!
Trusting Your Hosting Provider
If your website is big or small, handing over your online presence to a third-party is a big deal. You are whole-heartedly trusting a company to house your website with tender loving care. Any downtime and slow loading times can negatively impact your client base and SEO.
I've learnt that a hosting provider could have many 5 star reviews and still lack the infrastructure and support to back it up. In fact, this is what perplexed me about A2 Hostings many positive reviews.
Finding quality and appropriately priced hosting is very difficult to find. There are so many options, but the hosting industry has the classic issue of quantity over quality.
Backups
Regardless of how good any hosting company is, I would always recommend you take suitable measures to regularly carry out offsite backups on all your sites. Yes, this can be a laborious task if you are managing many sites, but its the only way to 100% sure you can be in control.
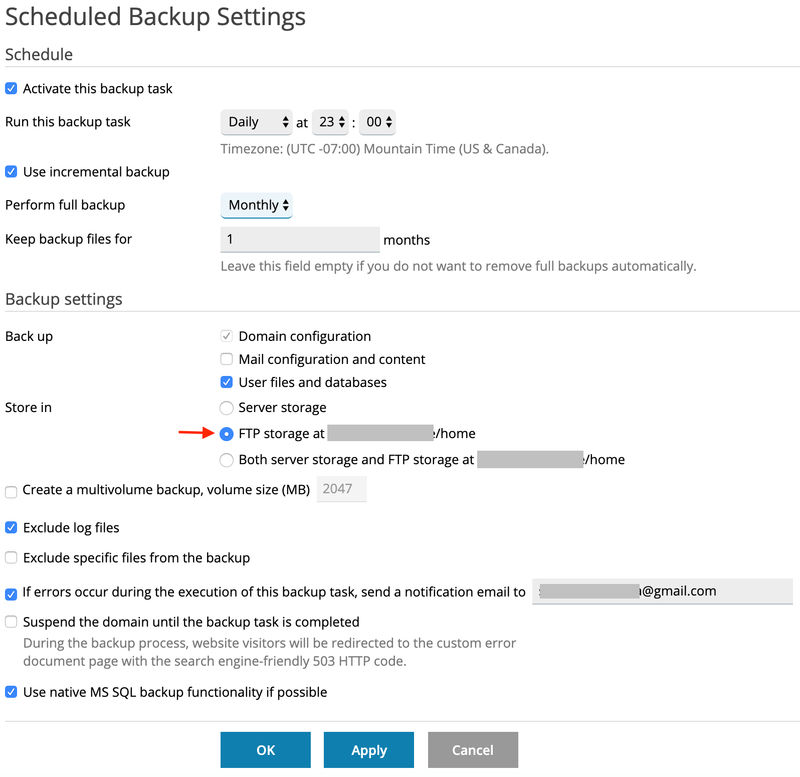
This was the only way I was able to move swiftly back to SoftSys Hosting and not wait on A2 Hosting to restore their services. At one point, there was a question mark over the current state of A2 Hosting's backups are in.

(A2 Hosting Questionable Backups)
Moving Back To Previous Hosting
Believe or not, I can't remember the exact reason why I left Softsys Hosting. After all, I never had any issues with them throughout the 9 years I was with them. Very accommodating bunch of guys! I think what attracted me to A2 Hosting was their shiny website, the promise of faster load times and the option to have my site hosted on UK servers.
It's always an absolute pain having to move and set everything back up again. But thanks to Ruchir at Softsys Hosting who was very attentive in helping me during my predicament and answering all my queries, managed to assist in achieving a quick turnaround. So in total, my site was only down for just under 2 days.
It seems quite apt that I come back to the hosting provider I call home under the same reasons to why I started using them in the first place back in 2009 when I was failed by my first ever hosting provider (Ultima Hosts). Oh, the irony!
Conclusion
Unfortunately, there isn't an exact science to finding the most ideal hosting provider for your budget and requirements. If you ever have any qualms regarding your current hosting provider, you might have good reason to be. Hosting should be worry and hassle free, knowing that your data is in the hands of capable people. If you have the finances to move, just do it. Hardware can be replaced, data can not. Data is a commodity!
Take online reviews with a pinch of salt. Instead, take a look at the existing users responses through their main Twitter and status accounts. Some might even have status pages. This will hopefully give you a more unbiased view on their operation and approach to resolving past issues.
Update - 26/04/2019
I have asked A2 Hosting for some form of compensation, especially since I purchased 2 years up front. Awaiting their response to the exact amount. I am hoping they will add some additional compensation as a goodwill gesture for misleading on their Kentico host offering.
Update - 27/04/2019
As of 27/04/2019 8pm (GMT), I managed to log back into A2 Hosting Plesk Administration to get a more recent backup of my hosting. Noticed there were some database errors in the process.
Update - 01/05/2019
Not looking good. I think there is a very slim chance in getting any form of reimbursement from A2 Hosting as they have decided to delete my support ticket. Not "close", but actually delete. I thought this was probably a mistake and after delving into the mass of responses from many other unhappy users, it seems I am not the only one.
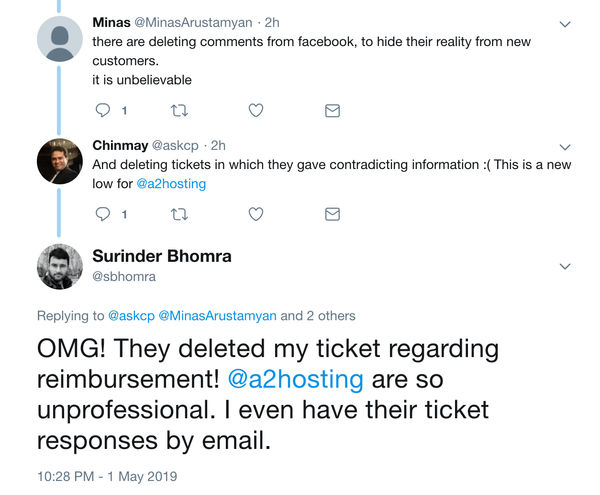
One can only assume that A2 Hosting are wiping their hands of any form of user correspondence. There hasn't been any further considerable updates or timescales to when services will resume. I am still awaiting for the ability to carry out a proper backup.