5 Hours Of GoDaddy Pro Is More Than Enough For Me
![]() There's a saying that goes along the lines of: if it ain't broke don't fix it. But as human beings, we're a very inquisitive bunch and like to delve into the dark abyss of the unknown just to see what's out there. This is exactly what I did when I decided to move hosting providers.
There's a saying that goes along the lines of: if it ain't broke don't fix it. But as human beings, we're a very inquisitive bunch and like to delve into the dark abyss of the unknown just to see what's out there. This is exactly what I did when I decided to move hosting providers.
I've hosted my site for many years very happily on SoftSys Hosting ever since UltimaHosts decided to delete my site, with no backup to restore. Now when a hosting company does that, you know it's time to move on - no matter how good they say they are. If I have no issues with my current hosting provider, why would I ever decide to move? Afterall, my site uptime has been better than it has ever been and the support is top notch!
Why Make The Move To Go Daddy Pro?
Well, for starters the cost of hosting was not something to be sniffed at and based on my current site usage, the deluxe package (priced at £3.99 per month) on top of a promo code - an absolute bargain! Secondly, the infrastructure that consists of real-time performance and uptime monitoring (powered by NodePing) and high spec servers Go Daddy describe as:
Hosting isn’t about having the best hardware, but it sure doesn’t hurt. Our servers are powered by Intel Xeon processors for heavy lifting, blazing-fast DDR 3 memory for low latency, and high speed, redundant storage drives for blistering page load times and reliability.
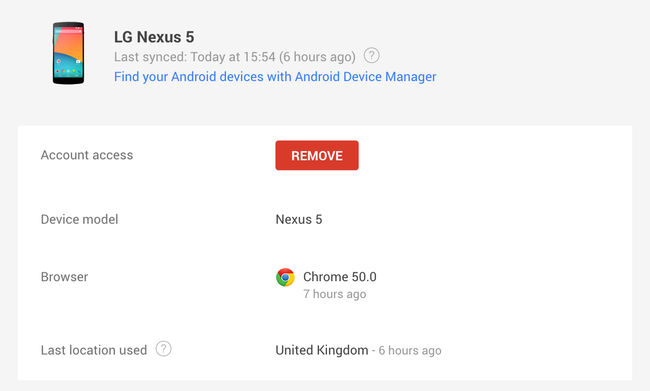
Currently, my server is based in the US and wanted to house my website on servers nearer to home back in the UK, which unfortunately my existing shared hosting package does not offer. Even though it doesn't look it, my website is quite large and there are benefits in having hosting in the same locale to where you live, such as faster upload and download speeds when having to update a website via FTP.
Thirdly, to have my domain and website all under a single dashboard login that Go Daddy seems to do well in a clean manageable interface and have the ability to self administer an SSL certificate without paying the hosting company for installation on my behalf.
Lastly, the 24/7 support accessible through either email or online chat, where GoDaddy Pro boasts its low waiting time and highly specialised support that can be escalated to resolve problems quickly. But from what I experienced, it was at this the very point where they failed.
The Extremely Painful Support Experience
I kid you not, it made me want to smack myself over the head repeatedly with my Macbook Pro. My experience with GoDaddy Pro's "specialised support" personnel was a painful one. For explanation purposes, I will call the person I spoke to: Gary.
After uploading files onto my GoDaddy Pro account, I carried out all initial setup with ease and was near enough ready to go. However, I was missing one critical piece of the puzzle that would demonstrate the low technical acumen of GoDaddy Pro support and thus my departure from their services. The critical piece being: the ability to upload and restore a backup of an MS SQL Server database.
Now, the SQL Server database backup in question is around 150MB and could not simply access the online MS SQL portal to allow me to upload my backup since the URL to the portal uses a sub domain (if I remember correctly) based on your own live website domain. This was a problem for me purely because I have not pointed the domain over to Go Daddy's servers. If I did, the consequence would be my current site going down. Not an option! I required a temporary generated domain that would allow me to not only access the MS SQL portal but also test my site before I re-point my domain.
My query was quite a simple one, so I opened up GoDaddy's support chat window and Gary came online to help. After much discussion he did not seem to understand why I'd want to do this and never managed to resolve the access issue to the MS SQL portal. All Gary did is send me links to documentation, even though I told him I have read the support literature beforehand and there was nothing relating to my original query.
He then suggested that I log into the database through Microsoft Management Studio and then go through the process of restoring my backup directly from my computer to their database. As we all know, (unfortunately Gary didn't) you cannot upload and restore a database backup directly from your own computer. The backup needs to be on the database server itself and even after I told him I am a Microsoft .NET Developer and that this was not possible, Gary kept telling me I was wrong. This went on for quite sometime and got to the point where I just couldn't be bothered anymore and any motivation I had on moving hosting providers dissolved in that very instant.
On one hand, I cannot falter Go Daddy's support response. It is pretty instant. On the other hand, the quality of support I had received is questionable to say the least.
Outcome
I decided to stay with SoftSys Hosting based on the fact I haven't had any issues and any queries I've ever had was dealt professionally and promptly. I think it's quite difficult to see how good you have it until you try something less adequate. Their prompt support exceeded my expectations when I requested an SSL to be installed on a Sunday evening and to my surprise it was all done when I got up the next morning. Now that's what I call service!
If I can say anything positive about my GoDaddy experience is the money back promise within 30 days of purchase. I had no problems getting a full refund swiftly. I spoke to the friendly customer service fellow over the phone and explained why I wanted to leave and my refund was processed the next working day.
I just wish I could get those 5 wasted hours of my life back...


 I've been meddling around with ReactJS over the last week or so, seeing if this is something viable to use for future client projects. I am always constantly on the lookout to whether there are better alternatives on how my fellow developers and I develop our sites.
I've been meddling around with ReactJS over the last week or so, seeing if this is something viable to use for future client projects. I am always constantly on the lookout to whether there are better alternatives on how my fellow developers and I develop our sites.